|
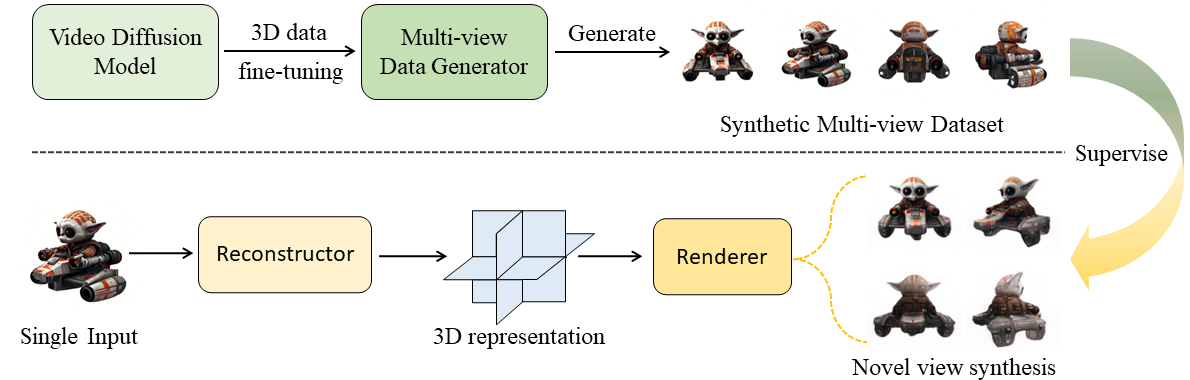
This paper presents a novel method for building scalable 3D generative models utilizing pre-trained video diffusion models. The primary obstacle in developing foundation 3D generative models is the limited availability of 3D data. Unlike images, texts, or videos, 3D data are not readily accessible and are difficult to acquire. This results in a significant disparity in scale compared to the vast quantities of other types of data.
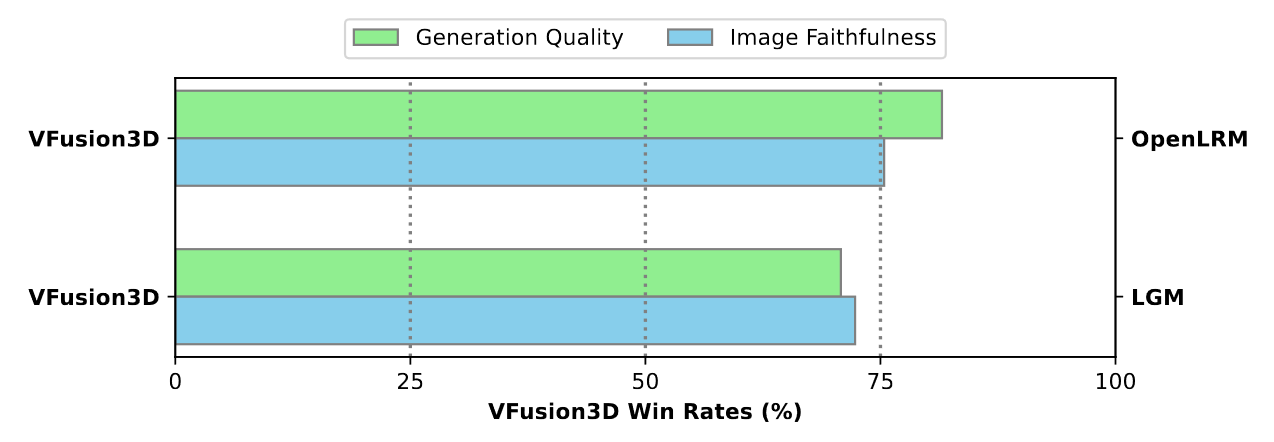
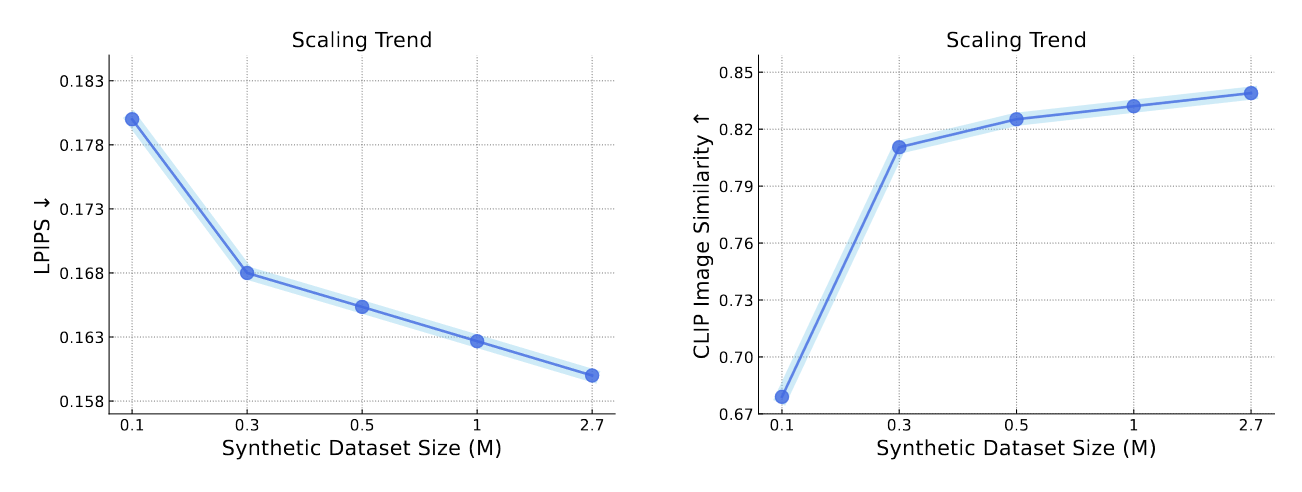
To address this issue, we propose using a video diffusion model, trained with extensive volumes of text, images, and videos, as a knowledge source for 3D data. By unlocking its multi-view generative capabilities through fine-tuning, we generate a large-scale synthetic multi-view dataset to train a feed-forward 3D generative model. The proposed model, VFusion3D, trained on nearly 3M synthetic multi-view data, can generate a 3D asset from a single image in seconds and achieves superior performance when compared to current SOTA feed-forward 3D generative models, with users preferring our results over 90% of the time.
|