|
|
|
|
|
|
|
|
|
|
|
|
|
| This paper studies the problem of measuring and predicting how memorable an image is to pattern recognition machines, as a path to explore machine intelligence. Firstly, we propose a self-supervised machine memory quantification pipeline, dubbed ``MachineMem measurer'', to collect machine memorability scores of images. Similar to humans, machines also tend to memorize certain kinds of images, whereas the types of images that machines and humans memorialize are different. Through in-depth analysis and comprehensive visualizations, we gradually unveil that "complex" images are usually more memorable to machines. We further conduct extensive experiments across 11 different machines (from linear classifiers to modern ViTs) and 9 pre-training methods to analyze and understand machine memory. This work proposes the concept of machine memorability and opens a new research direction at the interface between machine memory and visual data. |
|
|
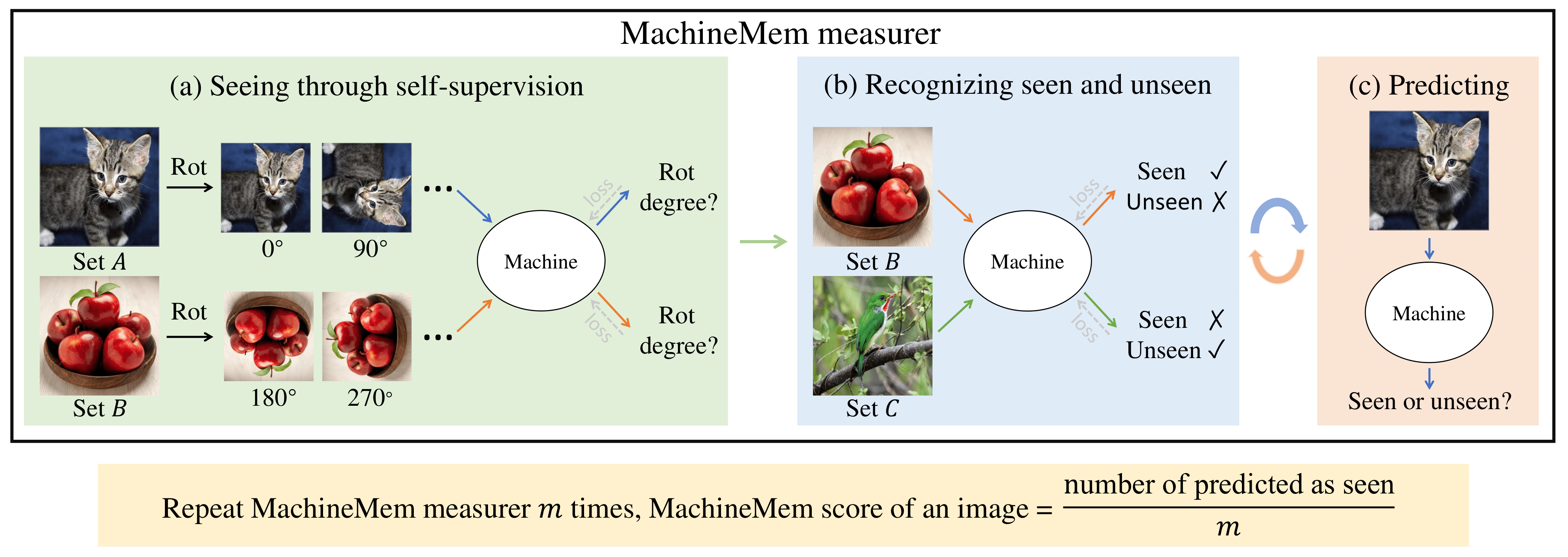
| A realization of the MachineMem measurer. Our MachineMem measurer has three stages: (a) Seeing images through self-supervision, (b) Recognizing seen and unseen images, and (c) Predicting whether an image has been seen. Each image presented here (cat, apple, and bird) denotes an image set (A, B, and C) containing n images. We are interested in measuring MachineMem scores of set A. In each episode of the MachineMem measurer, we randomly draw set B and set C from a large dataset while keeping the cat set identical. MachineMem scores of set A are obtained by repeating MachineMem measurer m times. |
| Design idea: The design of the MachineMem measurer follows the key idea used in the visual memory game, that is, quantifying machine memory through a repeat detection task. The visual memory game can be summarized using 3 keywords: see, repeat, and detect. We design the MachineMem measurer as a 3-stage pipeline, where each stage corresponds to a keyword. |
|
Collecting MachineMem scores with the MachineMem measurer can be time-consuming. Thereby, we trained our MachineMem predictor and HumanMem predictor.
Upload your image to see how memorable it is! |
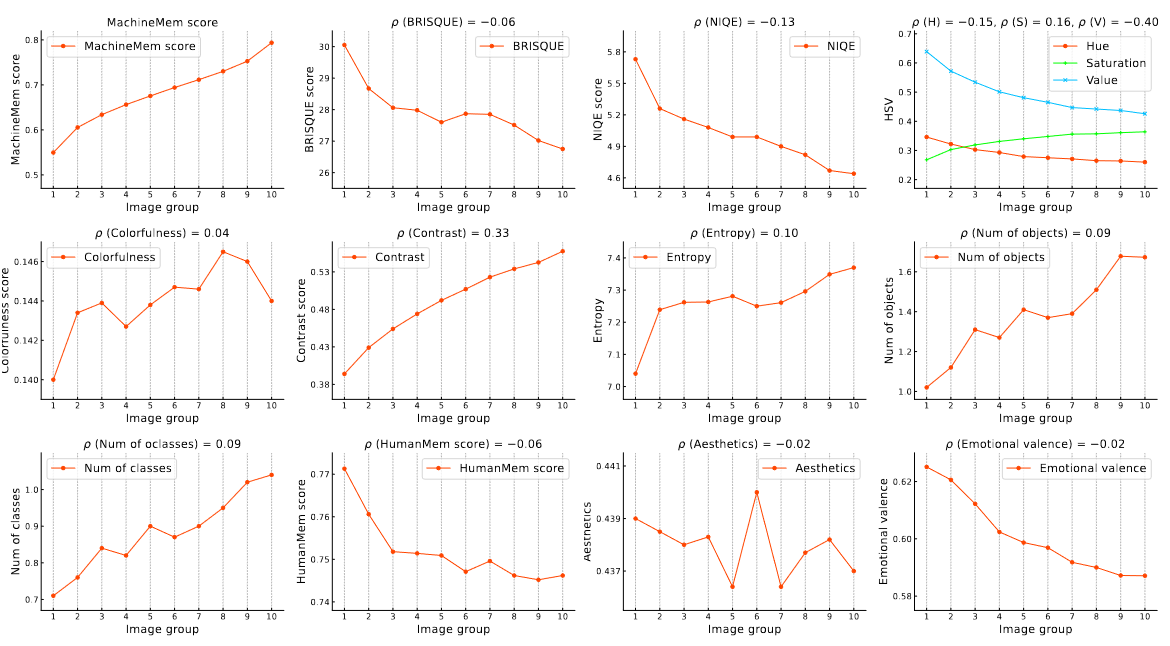
| Are image attributes enough to determine whether images will be memorable to machines? We study 13 image attributes. |
|
| We sort all LaMem images and group them into 10 groups, from the group with a mean of lowest MachineMem scores to the highest. Value and contrast are the two most notable attributes that correlate moderately (ρ ≥ 0.3) with MachineMem scores. Spearman’s correlation (ρ) is computed based on all data (58741 laMem images). |
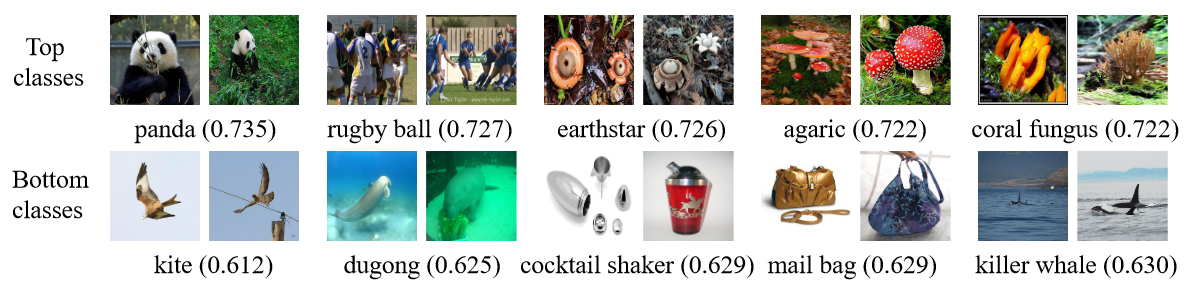
| Do images belonging to certain classes tend to be more or less memorable to machines? We use the MachineMem predictor to predict MachineMem scores of all ImageNet training images to obtain mean MachineMem scores of 1000 (ImageNet) classes. |
|
| We report the top-5 and bot-5 classes and their mean MachineMem scores. The top classes tend to have lower value and stronger contrast. The bottom classes usually have light backgrounds covering a large percentage of pixels. |
| Some hidden factors that may make an image more memorable to machines are still veiled. Thereby, we utilize the power of GANalyze to discover hidden factors that might determine MachineMem scores. |

|
| We summarize 6 trends, where the first 3 of them (value, contrast, and number of objects) are previously shown. For certain objects, viewing angle, shape, and tasty are hidden trends that are unveiled by GANalyze. An overall trend is that GANalyze is often complexifying images to make them more memorable to machines. |
| MachineMem scores and HumanMem scores are very weakly correlated. But in GANalyze, which is good at showing global trends, we find machines tend to memorize more complex images, which is on the reverse side of humans that are usually better at memorializing simple images. |

|
| HumanMem scores are labeled in red while blue indicates MahinceMem scores. Generally speaking, simple images are more memorable to humans while complex images are more memorable to machines. |
|
HumanMem is an intrinsic and stable property of an image that is shared across different humans, that is, though humans have dissimilar backgrounds, their memory regarding visual data is similar. So how about machines?
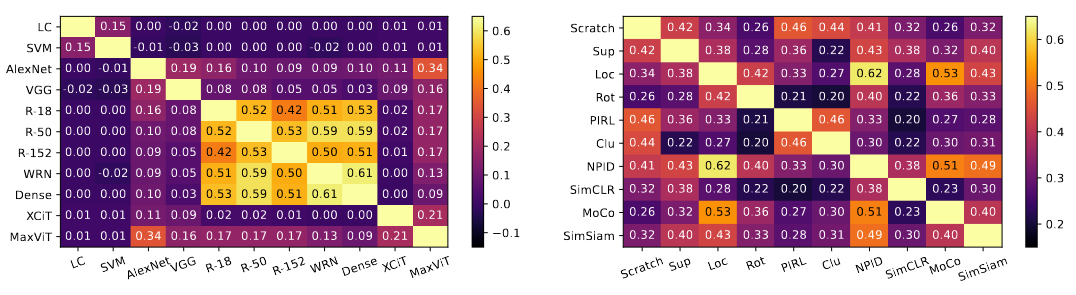
Here we explore two questions to shed light on understanding machine memory: Will MachineMem scores keep consistent across different machines (left)? What is the role of varied pre-training knowledge (right)? |
|
|
Spearman's correlation (ρ) of two machines/methods is presented at each off-diagonal.
left: Machines within each category (conventional machines, classic CNNs, modern CNNs, and recent ViTs) usually show strong correlations. However, machines across each category do not show obvious correlations most of the time. right: For an identical structured machine, MachineMem can be treated as an intrinsic and stable property of an image that is shared across different backgrounds (pre-training knowledge). |
 |
Han et al. What Images are More Memorable to Machines? preprint (hosted on ArXiv) (Code) |
Acknowledgements |